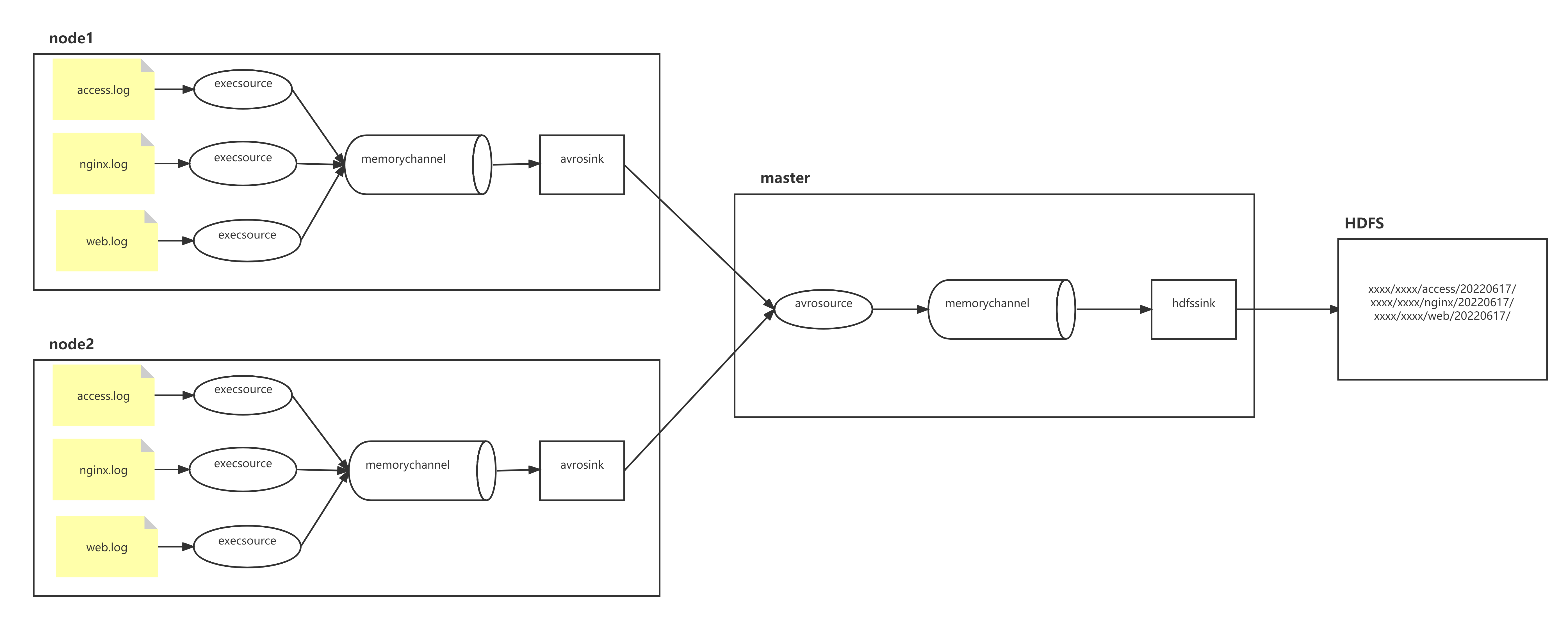
1.DQL语法
select 字段列表
from 表名列表 #DQL是可以进行多表查询的
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数2.基本查询(select)
2.1查询多字段
select 字段1,字段2,字段3,......from 表名;
select * from 表名;
#显示表内所有数据
#这条命令最好不要用,影响执行效率2.2设置别名
select 字段1 [as] 别名1,字段2 [as] 别名2,字段3 [as] 别名3......from 表名;
#这条语句的作用就是,让查询结果中的字段名显示为别名,看起来更清晰
#as可以省略
2.3去除重复记录
select distinct 字段列表 from 表名;3.条件查询(where)
select 字段列表 from 表名 where 条件列表;where后的条件列表有很多种
| 比较运算符 | > | 大于 |
| < | 小于 | |
| >= | 大于等于 | |
| <= | 小于等于 | |
| <>或!= | 不等于 | |
| = | 等于 | |
| in(...) | 括号内的值多选一,类似于多个或运算 | |
| like 占位符 | 模糊匹配。 _匹配单个字符,%匹配多个字符 | |
| is null | 查询为空的数据 | |
| between A and B | 在A到B的范围内(包含A、B,A必须>B) | |
| 逻辑运算符 | and或&& | 与,多个条件同时成立 |
| or或|| | 或,多个条件任意一个成立 | |
| not或! | 非,条件不成立 |
(1)between...and...
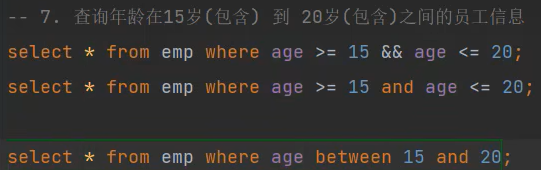
(2)in(...)

(3)like 占位符

4.聚合函数(count、max、min、avg、sum)
select 聚合函数(字段名) from 表名;
| 聚合函数 | 功能 |
| count | 统计数量 |
| max | 求最大值 |
| min | 求最小值 |
| avg | 求平均值 |
| sum | 求和 |
聚合函数是不对null值进行运算的(包括count)
5.分组查询(group by、having)
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
#where条件是在分组前生效的,having条件是对分组后的字段生效的
#where不可以对聚合函数进行判断,having可以对聚合函数进行判断
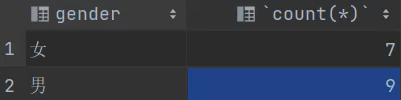
上图语句中的第一个gender使结果出现了"男、女",如果省略掉,则只会得到2个数值
count(*)可以当做被检索的目标,因此也就代替了select后的*,也就是字段列表。也就是说,当有聚合函数出现时,select后面就不再跟字段列表了
分组查询往往配合聚合函数进行使用

select workaddress,count(*) from emp group by workaddress;
#这条语句会显示每个地址的人数
select workaddress,count(*) from emp where age < 45 group by workaddress;
#这条语句会显示每个地址下年龄小于45的人数
select workaddress,count(*) from emp where age < 45 group by workaddress having count(*) >= 3;
#对于每个地址下年龄小于45的人数,这条语句会显示这个人数大于等于3的地址与人数执行顺序是where > 聚合函数 > having
6.排序查询
select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2......;
#排序方式有2种:ASC、DESC,分别代表升序和降序。如果不填,则默认为升序
#order by后出现多个字段排序时,会在第一个字段相同时,再对第二个字段进行排序
7.分页查询
select 字段列表 from 表名 limit 起始索引,查询记录数;*起始索引=(查询页码-1)*每页显示记录数
*分页查询的关键词在不同的数据库中是不同的,mysql的关键词是limit
*如果查询的是第一页数据,起始索引可以省略

8.执行顺序
如下图所示,蓝色关键字代表语法顺序,红色圈数字代表执行顺序